Cómo diseñar un sistema estéreo integrado personalizado para la percepción de la profundidad

Existen varias opciones de sensores 3D para desarrollar sistemas de percepción de la profundidad, como la visión estéreo con cámaras, el sistema LiDAR y los sensores de tiempo de vuelo. Cada opción tiene sus puntos fuertes y débiles. Un sistema estéreo es generalmente barato, lo suficientemente resistente para su uso en exteriores, y puede proporcionar una nube de puntos de color de alta resolución.
Actualmente existen en el mercado varios sistemas estéreo a la venta. En función de factores como la precisión, la referencia, el campo de visión y la resolución, los ingenieros de sistemas deben en ocasiones diseñar un sistema a medida para satisfacer los requisitos específicos de la aplicación.
Este artículo describe en primer lugar las partes principales de un sistema de visión estéreo y, a continuación, describe los pasos para construir una cámara estéreo personalizada utilizando componentes de hardware existentes y software de código abierto. Como esta configuración está orientada a la integración, calculará un mapa de profundidad de cualquier escena en tiempo real, sin necesidad de un equipo host. En otro artículo, se analiza cómo diseñar un sistema estéreo personalizado para utilizarlo con un equipo host cuando el espacio es menos limitado.
Otra aplicación que puede beneficiarse enormemente de un sistema de procesamiento integrado de este tipo es la detección de objetos. Con los avances en el aprendizaje profundo, se ha vuelto relativamente fácil agregar detección de objetos a las aplicaciones, pero la necesidad de recursos de GPU dedicados lo hace prohibitivo para muchos usuarios. En este artículo, también analizamos cómo agregar aprendizaje profundo a su aplicación de visión estéreo sin la necesidad de una costosa GPU host. Hemos dividido el código de ejemplo y las secciones de este artículo en visión estéreo y aprendizaje profundo, por lo que si su aplicación no requiere aprendizaje profundo, no dude en omitir las secciones correspondientes.
Descripción general de la visión estéreo
La visión estéreo es la extracción de información 3D a partir de imágenes digitales mediante la comparación de información sobre una escena desde dos puntos de vista. Las posiciones relativas de un objeto en dos planos de la imagen proporcionan información sobre la profundidad del objeto desde .
La Figura 1 muestra una descripción general de un sistema de visión estéreo que consta de los siguientes pasos clave:
- Calibración: La calibración de la cámara se refiere tanto a la intrínseca como a la extrínseca. La calibración intrínseca determina el centro de la imagen, la distancia focal y los parámetros de distorsión, mientras que la calibración extrínseca determina las posiciones 3D de las cámaras. Este es un paso crucial en muchas aplicaciones de visión artificial, sobre todo cuando se requiere información métrica de la escena, como la profundidad. La etapa de calibración se analizará en detalle en la sección 5.
- Rectificación: La rectificación estéreo se refiere al proceso de reproyección de los planos de la imagen en un plano común paralelo a la línea entre los centros de las cámaras. Tras la rectificación, los puntos correspondientes se encuentran en la misma fila, lo que reduce en gran medida el coste y la ambigüedad del emparejamiento. Este paso se realiza en el código proporcionado para diseñar un sistema propio.
- Emparejamiento estéreo: Se refiere al proceso de emparejamiento de píxeles entre las imágenes izquierda y derecha, que genera imágenes de disparidad. El algoritmo de coincidencia semiglobal (SGM) se utilizará en el código proporcionado para diseñar un sistema propio.
- Triangulación: La triangulación se refiere al proceso de determinar un punto en el espacio 3D dada su proyección en las dos imágenes. La imagen de disparidad se convertirá en una nube de puntos 3D.
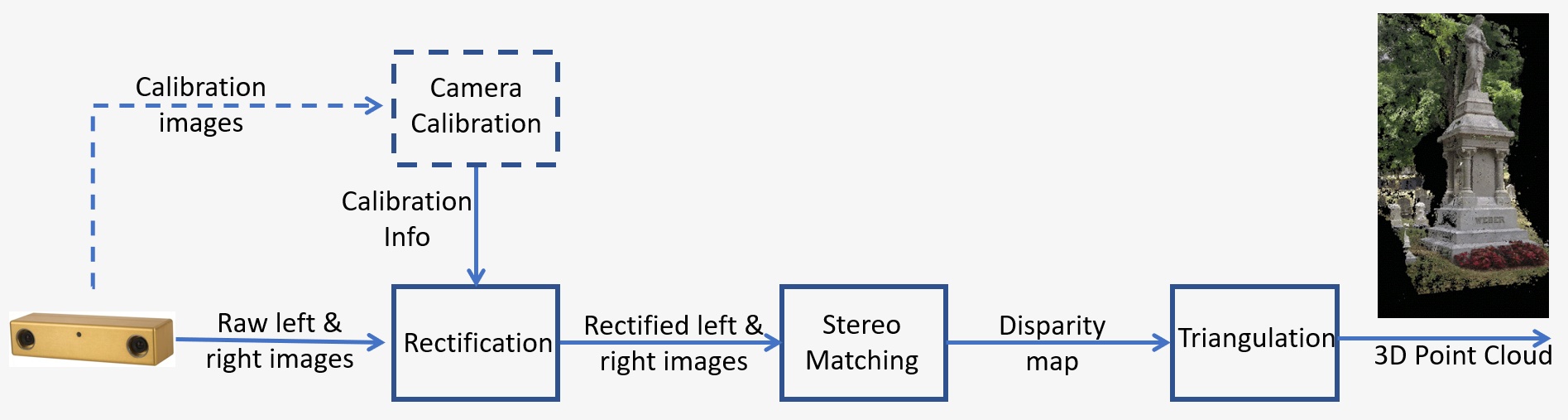
Figura 1: Descripción general de un sistema de visión estéreo
Información general sobre el aprendizaje profundo
El aprendizaje profundo es un subcampo del aprendizaje automático que se ocupa de algoritmos inspirados en la estructura y la función del cerebro. Trata de imitar la capacidad de aprendizaje del cerebro humano. Los algoritmos de aprendizaje profundo pueden realizar operaciones complejas como el reconocimiento, la clasificación y la segmentación de objetos, entre otras, de manera eficiente. Entre otras cosas, el aprendizaje profundo permite a las máquinas reconocer personas y objetos en las imágenes que se le alimentan. La aplicación particular que nos interesa es la de detección de personas. El entrenamiento de sus propios algoritmos de aprendizaje profundo requiere una gran cantidad de datos de entrenamiento etiquetados, pero los modelos de código abierto entrenados previamente facilitan el desarrollo de estas aplicaciones.
El aprendizaje profundo también requiere GPU de alto rendimiento, pero la solución Quartet para TX2 viene con todas las capacidades de una GPU más grande a una fracción del factor de forma y el consumo de energía. Tener los modelos de aprendizaje profundo ejecutándose en el TX2 también tiene el beneficio adicional de la movilidad, por lo que es un candidato perfecto para los robots móviles que necesitan detectar a personas para mantenerse alejados de ellas.
Ejemplo de diseño
Ejemplo de diseño de sistema estéreo. Estos son los requisitos para una aplicación de robot móvil en un entorno dinámico con objetos que se mueven rápidamente. La escena de interés tiene un tamaño de 2 m, la distancia entre las cámaras y la escena es de 3 m y la precisión deseada es de 1 cm a 3 m.
Para obtener más detalles sobre la precisión estéreo, consulte este artículo. El error de profundidad viene dado por: ΔZ=Z²/Bf * Δd que depende de los siguientes factores:
- Z es el rango
- B es la referencia
- f es la distancia focal en píxeles, que está relacionada con el campo de visión de la cámara y la resolución de la imagen
Hay varias opciones de diseño que pueden cumplir estos requisitos. En función del tamaño de la escena y de la distancia requerida anteriormente, se puede determinar la distancia focal del objetivo para un sensor concreto. Además de la referencia, se puede utilizar la fórmula anterior para calcular el error de profundidad esperado a 3 m, y comprobar que cumple con el requisito de precisión.
La figura 2 muestra dos opciones: utilizar cámaras de menor resolución con una referencia más larga o cámaras de mayor resolución con una más corta. La primera opción es una cámara más grande, pero tiene una menor necesidad computacional, mientras que la segunda opción es una cámara más compacta, pero con una mayor necesidad computacional. Para esta aplicación, es preferible la segunda opción, ya que el tamaño compacto es más conveniente para el robot móvil y se puede utilizar la Solución integrada Quartet para TX2, que tiene una potente GPU integrada para satisfacer los requisitos de procesamiento.

Figura 2: Opciones de diseño de sistema estéreo para un ejemplo de aplicación
Requisitos de hardware
Para este ejemplo, se montaron dos cámaras Blackfly S Board Level de 1,6 MP con el sensor de obturación global Sony Pregius IMX273 en una barra impresa 3D separada 12 cm. Ambas cámaras tienen lentes de montura S de 6 mm similares. Las cámaras se conectan a la placa portadora personalizada TX2 de la solución integrada Quartet mediante dos cables FPC. Para sincronizar las cámara izquierda y derecha y capturar imágenes al mismo tiempo, se utiliza un cable de sincronización que conecta las dos cámaras. La figura 3 muestra las vistas frontal y posterior del sistema estéreo integrado personalizado.

Figura 3: Vistas frontal y posterior del sistema estéreo integrado personalizado
La siguiente tabla enumera todos los componentes de hardware:
|
Pieza |
Descripción |
Cantidad |
Vínculo |
|
ACC-01-6005 |
Portadora Quarter con módulo TX2 de 8 GB |
1 |
https://www.flir.com/products/quartet-embedded-solution-for-tx2/ |
|
BFS-U3-16S2C-BD2 |
1,6 MP, 226 FPS, Sony IMX273, Color |
2 |
|
|
ACC-01-5009 |
Montura S y filtro IR para cámaras BFS color Board Level |
2 |
|
|
BW3M60B-1000 |
Lentes de montura S de 6 mm |
|
http://www.boowon.co.kr/site/ |
|
ACC-01-2401 |
Cable FPC de 15 cm para Blackfly S Board Level |
2 |
https://www.flir.com/products/15-cm-fpc-cable-for-board-level-blackfly-s/ |
|
XHG302 |
Disipador de calor activo NVIDIA® Jetson™ TX2/TX2 4GB/TX2i |
1 |
https://connecttech.com/product/nvidia-jetson-tx2-tx1-active-heat-sink/ |
|
Cable de sincronización (haga el suyo propio) |
1 |
||
|
Barra de montaje (haga la suya propia) |
1 |
Ambas lentes deben ajustarse para enfocar las cámaras en el rango de distancias que su aplicación requiere. Apriete el tornillo (rodeado con un círculo rojo en la figura 4) de cada lente para mantener el enfoque.

Figura 4: Vista lateral del sistema estéreo mostrando el tornillo de la lente
Requisitos de software
a. Spinnaker
Teledyne FLIR Spinnaker SDK está preinstalado en las soluciones integradas Quartet para TX2. Spinnaker es necesario para comunicarse con las cámaras.
b. OpenCV 4.5.2 compatible con CUDA
La versión 4.5.1 o posterior de OpenCV es necesaria para SGM, el algoritmo de coincidencia estéreo utilizado. Descargue el archivo zip que contiene el código de este artículo y descomprímalo en la carpeta StereoDepth. El script para instalar OpenCV es OpenCVInstaller.sh. Escriba los siguientes comandos en un terminal:
- cd ~/StereoDepth
- chmod +x OpenCVInstaller.sh
- ./OpenCVInstaller.sh
El instalador le pedirá que escriba su contraseña de administrador. A continuación, comenzará la instalación de OpenCV 4.5.2. Puede tardar un par de horas en descargar y crear OpenCV.
c. Inferencia de Jetson (si se requiere aprendizaje profundo)
La inferencia de Jetson es una biblioteca de código abierto de NVIDIA que se puede usar para el aprendizaje profundo acelerado por GPU en dispositivos Jetson, como el TX2. La biblioteca utiliza el SDK de TensorRT, que facilita la inferencia de alto rendimiento en las GPU NVIDIA. La inferencia de Jetson proporciona al usuario una matriz de modelos de aprendizaje profundo previamente entrenados y listos para usar y el código para implementar estos modelos mediante TensorRT. Para instalar la inferencia de Jetson, escriba los siguientes comandos en una terminal:
- cd ~/StereoDepth
- chmod +x InferenceInstaller.sh
- ./InferenceInstaller.sh
Calibración
El código para obtener imágenes estéreo y calibrarlas se encuentra en la carpeta “Calibration”. Utilice la interfaz gráfica de usuario de SpinView para identificar los números de serie de las cámaras izquierda y derecha. En esta configuración, la cámara derecha es la maestra y la izquierda la esclava. Copie los números de serie de las cámaras maestra y esclava en las líneas 60 y 61 del archivo grabStereoImages.cpp. Diseñe los archivos ejecutables utilizando los siguientes comandos en un terminal:
- cd ~/StereoDepth/Calibration
- mkdir build
- mkdir -p images/{left, right}
- cd build
- cmake ..
- make
Imprima el patrón de tablero de ajedrez desde este enlace y fíjelo a una superficie plana para usarlo como objetivo de calibración. Para obtener los mejores resultados durante la calibración, en SpinView, desactive la exposición automática y ajuste la exposición para que el patrón de tablero de ajedrez esté claro y los cuadrados blancos no estén sobreexpuestos, como se muestra en la figura 5. Una vez recopiladas las imágenes de calibración, la ganancia y la exposición pueden ajustarse automáticamente en SpinView.
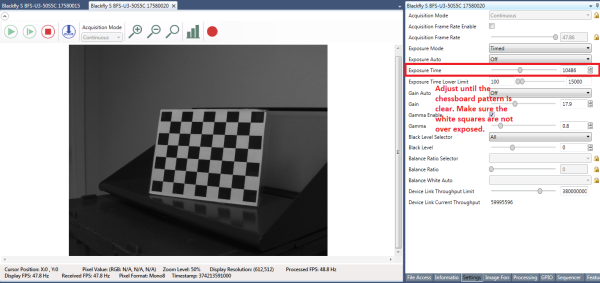
Figura 5: Configuración de la interfaz gráfica de usuario de SpinView
Para empezar a recopilar las imágenes, escriba
- ./grabStereoImages
El código debería empezar a recopilar imágenes a una velocidad aproximada de 1 FPS. Las imágenes de la izquierda se almacenan en la carpeta images/left y las imágenes de la derecha en images/right. Mueva el objetivo para que aparezca en cada esquina de la imagen. Puede girar el objetivo, tomar imágenes desde cerca y desde más lejos. Por defecto, el programa captura 100 pares de imágenes, pero se puede cambiar con el argumento de línea de comando:
- ./grabStereoImages 20
Esto solo recopilará 20 pares de imágenes. Tenga en cuenta que esto sobrescribirá cualquier imagen guardada previamente en las carpetas. La figura 6 muestra algunos ejemplos de imágenes de calibración.

Figura 6: Ejemplos de imágenes de calibración
Después de recopilar las imágenes, ejecute el código Python de calibración escribiendo:
- cd ~/StereoDepth/Calibration
- python cameraCalibration.py
Esto generará 2 archivos llamados “intrinsics.yml” y “extrinsics.yml”, que contienen los parámetros intrínsecos y extrínsecos del sistema estéreo. El código presupone un tamaño cuadrado de tablero de ajedrez de 30 mm por defecto, pero se puede editar si es necesario. Al final de la calibración, se muestra el error RMS, que indica la calidad de la calibración. El error RMS típico para una buena calibración debe ser inferior a 0,5 píxeles.
Mapa de profundidad en tiempo real
El código para calcular la disparidad en tiempo real se encuentra en la carpeta “Depth”. Copie los números de serie de las cámaras en las líneas 230 y 231 del archivo live_disparity.cpp. Diseñe los archivos ejecutables utilizando los siguientes comandos en un terminal:
- cd ~/StereoDepth/Depth
- mkdir build
- cd build
- cmake ..
- make
Copie los archivos “intrinsics.yml” y “extrinsics.yml” obtenidos en el paso de calibración a esta carpeta. Para ejecutar la demostración del mapa de profundidad en tiempo real, escriba:
- ./live_disparity
Se mostrará la imagen de la cámara izquierda (imagen sin procesar ni rectificar) y el mapa de profundidad (resultado final). La figura 7 muestra algunos ejemplos de los resultados. La distancia de la cámara está codificada por colores según la leyenda situada a la derecha del mapa de profundidad. La región negra en el mapa de profundidad significa que no se encontraron datos de disparidad en esa región. Gracias a la GPU NVIDIA Jetson TX2, puede ejecutar hasta 5 FPS a una resolución de 1440 × 1080 y hasta 13 FPS a una resolución de 720 × 540.
Para ver la profundidad en un punto concreto, haga clic en ese punto del mapa para que se muestre la profundidad, como se indica en el último ejemplo de la figura 7.

Figura 7: Ejemplo de imágenes de la cámara izquierda y el correspondiente mapa de profundidad. El mapa de profundidad que aparece a continuación también muestra la profundidad en un punto concreto.
Detección de personas
Utilizamos DetectNet proporcionado por la inferencia de Jetson para detectar humanos en un marco de imagen. DetectNet viene con opciones para seleccionar la arquitectura del modelo de aprendizaje profundo para la detección de objetos. Utilizamos la arquitectura de detección de disparo único (Single Shot Detection, SSD) con una red troncal MobileNetV2 para optimizar tanto la velocidad como la precisión. Al ejecutar la demostración por primera vez, TensorRT crea un motor en serie para optimizar aún más la velocidad de inferencia, que puede tardar unos minutos en completarse. Este motor se guarda automáticamente en archivos para posteriores ejecuciones. La arquitectura utilizada es bastante eficiente y se pueden esperar aproximadamente igual a 50 fps para ejecutar el módulo de detección. El código para la capacidad de detección de personas junto con la profundidad estéreo en tiempo real se encuentra en la carpeta “DepthAndDetection”. Copie los números de serie de las cámaras para archivar live_disparity.cpp líneas 271 y 272. Compile el ejecutable utilizando los siguientes comandos en un terminal:
- cd ~/StereoDepth/DepthAndDetection
mkdir
buildcd
buildcmake ..
make
Copie los archivos “intrinsics.yml” y “extrinsics.yml” obtenidos en el paso de calibración en esta carpeta. Para ejecutar la demostración del mapa de profundidad en tiempo real, escriba
- ./live_disparity
Se mostrarán dos ventanas que muestran las imágenes en color rectificadas a la izquierda y el mapa de profundidad. El mapa de profundidad está codificado por colores para una mejor visualización. Ambas ventanas tienen cuadros delimitadores que rodean a las personas en el marco y muestran la distancia promedio que existe hasta la persona desde la cámara. Con procesamiento estéreo e inferencia de aprendizaje profundo, la demostración se ejecuta a alrededor de aproximadamente igual a 4 fps a una resolución de 1440 × 1080 y a hasta 11,5 fps para una resolución de 720 × 540.

Figura 1: Ejemplo de imágenes de la cámara izquierda y el mapa de profundidad correspondiente. Todas las imágenes muestran a la persona detectada en las imágenes y la distancia de la persona de la cámara.
El algoritmo de detección de personas puede detectar a varias personas incluso en condiciones difíciles como la oclusión. El código calcula las distancias a todas las personas detectadas en la imagen, como se muestra a continuación.

Figura 2: La imagen de la izquierda y el mapa de profundidad muestran a varias personas detectadas en la imagen y su distancia correspondiente de la cámara.
Resumen
La visión estéreo para desarrollar la percepción de la profundidad presenta las ventajas de funcionar correctamente en exteriores, ser capaz de proporcionar un mapa de profundidad de alta resolución y ser muy asequible gracias a sus componentes de bajo coste. En función de las necesidades, existen en el mercado varios sistemas estéreo a la venta. Si necesita desarrollar un sistema estéreo integrado personalizado, puede hacerlo de forma muy sencilla siguiendo las instrucciones aquí descritas.
Artículos relacionados
-
Sistemas integrados
Cómo diseñar un sistema estéreo integrado personalizado para la percepción de la profundidad
Más información -
 Sistemas integrados
Sistemas integrados
Transmisión de cámaras 4x con placa portadora pequeña: Prototipo rápido
Lea la historia -
 Sistemas integrados
Sistemas integrados
Guía de integración de cámaras de nivel de placa
Lea la historia